Every week, NFL players get injured with varying degrees of severity. Not much data is available to the public related to injuries, weeks missed due to injury, or the type of injury sustained. The best source of public injury info can be found on PFR’s individual team injury page. While informative, the layout is not great for analysis and it is difficult to make any conclusions about team injuries. In this post, I:
- Develop a scraper for PFR injuries.
- Create a clean database of injuries to analyze.
- Provide general analysis on the relationship between defensive ability and health.
- Examine the correlation between injury history and future games missed.
Creating a List of URLs to Scrape
If you opened the linked page above, you would notice that each URL only contains a specific team and specific season. This means that to collect all of the injury data we will need a list of URLs for our future scraping function to run through. The key points in the URL are the PFR team abbreviation and the season of interest (data on PFR only goes back to 2009). First, we can start with assembling the list of team abbreviations. This is a little different than NFL Fast R abbreviations so if you don’t recognize an abbreviation don’t worry (Titans are oti which very confusing).
library(dplyr)
library(glue)
library(rvest)
library(stringr)
library(tidyr)
library(tidyverse)
teams = list( "crd", "atl", "rav", "buf", "car", "chi", "cin", "cle", "dal", "den", "det", "gnb", "htx", "clt", "jax", "kan", "sdg", "ram", "rai", "mia", "min", "nor", "nwe", "nyg", "nyj", "phi", "pit", "sea", "sfo", "tam", "oti", "was" )
Great! Now we can just create a list of years (2009 - 2020) and then write a loop that modifies the base PFR URL with all possible combinations of seasons and team abbreviations. One the loop finishes I perform some basic cleaning of the URLs for the web scraping function.
###List of years
years = list(2009:2020)
###Loop to create urls to scrape
url <- capture.output(
for (n in teams) {
for (a in years) {
###URL of interest
print(paste0("https://www.pro-football-reference.com/teams/",n,"/",a,"_injuries.htm"))
}
})
###Remove uneeded strings
url <- url%>%
noquote() %>%
substr(6,100) %>%
noquote()
url <- gsub('"', '', url)
And voila, we have all of the URLs we need to scrape PFR. Now comes the hard part, the table provided by PFR could be scraped by the html_table function in Rvest but that results in the scraper missing what the specific injury was for each player. Notice that on the team injury page, one has to hover over the player’s name and week to see what injury the player had. This is very important information, so the easiest approach of html_table can’t be used. Thus, I had to employ a more complex approach that required html_nodes.
Developing the Injury Scraper
There are a few distinct features of the scraper that were created to accomodate inconsistencies between each team page.
Problem 1. The aformentioned hidden text that describes what the injury is for each player can’t be scraped with html table. Solution: I use the “data tip” path to grab any injury info. The specific code is try(xml_attrs(team_url[[1]])[[“data-tip”]]). Note the try portion of the code, not every player has an injury note so this prevents the function from stopping if there is no data tip.
Problem 2. Different number of games played for each team (ranges from 17 to 20). Solution: I instruct the function to run through a sequence of 1 through 20. If a week beyond 16 is not detected, then the function will not malfunction as I inserted the try code again.
The function code can be found below, it is a bit lengthy but that is in part because of having to clean the messy output of bypassing html table.
###Function to scrape url of choice
Scraper <- function(urls){
dataframe = data.frame()
###URL of interest
url <- read_html(urls)
###Get roster of team from page along with season and team name
Rosters <- url %>%
html_nodes(xpath='//*[contains(concat( " ", @class, " " ), concat( " ", "left", " " ))]') %>%
html_text() %>%
as.data.frame() %>%
slice(1:(n()-1)) %>%
slice(-1) %>%
mutate(Team = url %>%
html_nodes(xpath = '//*[@id="meta"]/div[2]/h1/span[2]') %>%
html_text(),
Season = url %>%
html_nodes(xpath = '//*[@id="meta"]/div[2]/h1/span[1]') %>%
html_text()) %>%
dplyr::rename("Names"=".")%>%
mutate("Row" = row_number()) %>%
relocate(Row, .before = Names)
###Create blank data frames to move data into
test_frame <- data.frame(matrix(NA,nrow(Rosters), 20))
test_frame1 <- data.frame(matrix(NA,nrow(Rosters), 20))
test_frame2 <- data.frame(matrix(NA,nrow(Rosters), 20))
###Iterate through the number of columns and games. The max number of games is 20 so we set it as 1:20
for (x in 1:nrow(Rosters)) {
for (y in seq_along(1:20)) {
###Direct url of specific team to xpath that contains info about injury, active status, and week
team_url <- url %>%
html_nodes(xpath= paste('//*[@id="team_injuries"]/tbody/tr[',x,']/td[',y,']'))
###Active or inactive
test_frame[[x,y]] <- try(xml_attrs(team_url[[1]])[["class"]])
test_frame <- test_frame
###Week information
test_frame1[[x,y]] <- try(xml_attrs(team_url[[1]])[["data-stat"]])
test_frame1 <- test_frame1
###Injury info
test_frame2[[x,y]] <- try(xml_attrs(team_url[[1]])[["data-tip"]])
test_frame2 <- test_frame2
###Bind our rosters with the 3 pieces of info from above
df1 <- cbind(Rosters, test_frame)
df2 <- cbind(Rosters, test_frame1)
df3 <- cbind(Rosters, test_frame2)
###Make data longer for easier interpretation and rename variables
melt_1 <- reshape::melt(df1, id.vars=c("Row","Names", "Team", "Season"))%>%
dplyr::rename("Active_Inactive"=value)
melt_2 <- reshape::melt(df2, id.vars=c("Row","Names", "Team", "Season")) %>%
select(value) %>%
dplyr::rename("Week"=value)
melt_3 <- reshape::melt(df3, id.vars=c("Row","Names", "Team", "Season")) %>%
select(value) %>%
dplyr::rename("Injury"=value)
###If DNP is detected in the string then individual did not play, rename output to reflect this rather than long code
melt_1 <- melt_1 %>%
mutate("Active_Inactive" = ifelse(str_detect(melt_1$Active_Inactive, "dnp") == TRUE, "Out", "Active"))
###If the individual carried no designation then the data tip xpath returns an error, we detect this and replace the output with a healthy designation but leave actual injury if one is available. Also, seperate string to create new column and specific injury.
melt_3 <- melt_3 %>%
mutate("Game_Status" = ifelse(str_detect(melt_3$Injury, "subscript out of bounds") == TRUE, "Healthy", Injury)) %>%
select(-Injury) %>%
separate(Game_Status, c("Game_Designation", "Injury_Type"), ":")
###Fix blank values from above fix
melt_3[melt_3==" "]<-NA
melt_3[is.na(melt_3)]<-"None"
###Combine the data collected from above and remove uneeded columns, also remove the week_ text to just show week number
final <- cbind(melt_1,melt_2, melt_3) %>%
select(-Row, -variable) %>%
mutate(Week = str_remove_all(Week, "week_"))
###Make weeks numberic
final$Week <- as.numeric(final$Week)
final$Injury_Type = str_to_title(final$Injury_Type)
###Filter out any NAs or weeks that team did not play in
final <- final %>%
filter(Week < 100)
}
}
return(final)
}
###Create empty data frame to store data
empty <- data.frame()
###Create loop that will go through our urls and return injuryies
for (x in url) {
output <- Scraper(x)
empty <- rbind(empty, output)
}
###Our data
empty
Running the Scraper
Then we can run the scraper with the following loop.
###Create empty data frame to store data
empty <- data.frame()
###Create loop that will go through our urls and return injuries
for (x in url) {
output <- scraper(x)
empty <- rbind(empty, output)
}
Analysis of 2020 Injuries
Now the interesting part. We can graph who the most injured teams of 2020 were on both sides of the ball. Man games lost were calculated by summing the total missed games from rostered players throughout the season. For example, player x strained his hamstring and missed 8 games. He would acrue 8 man games lost by this methodology.
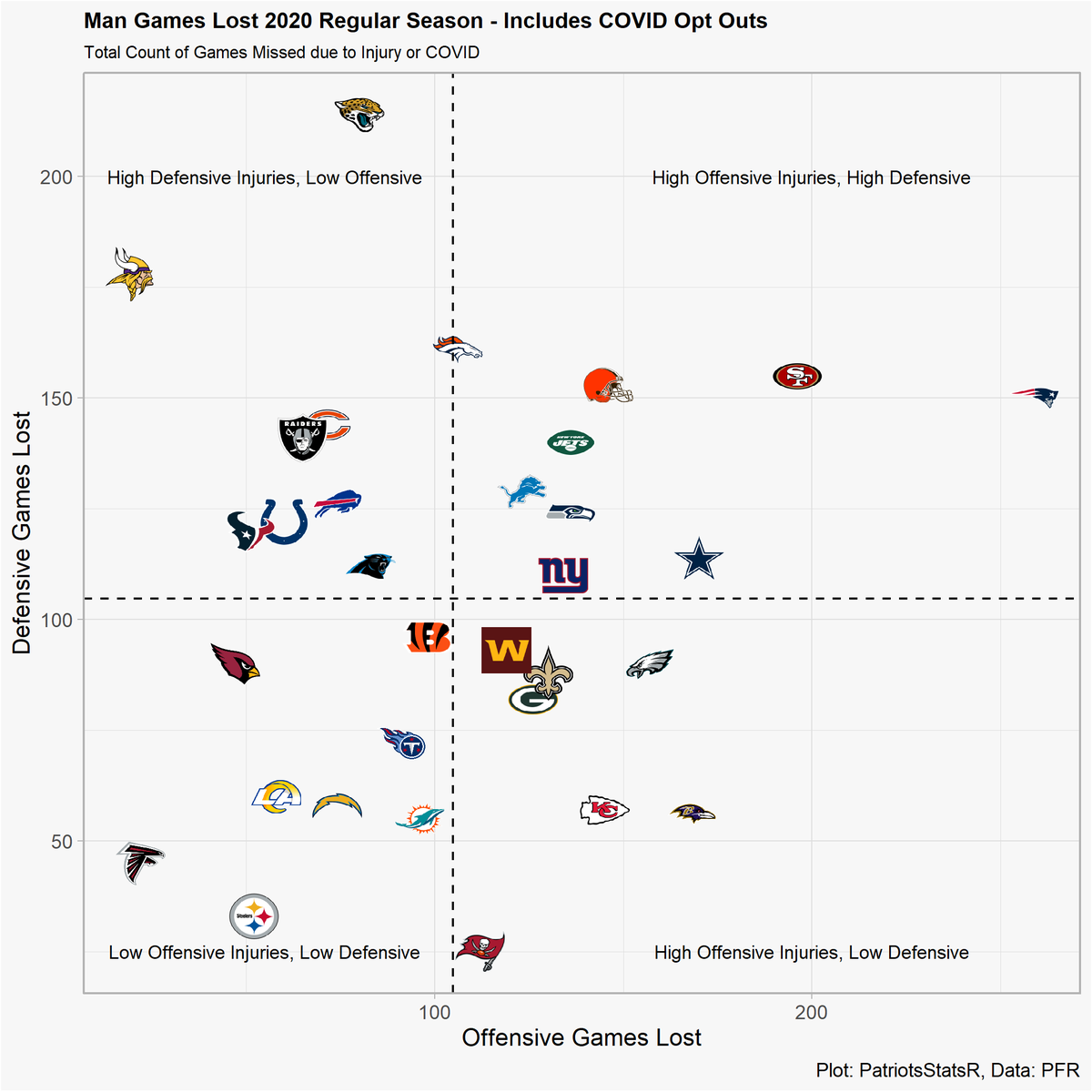
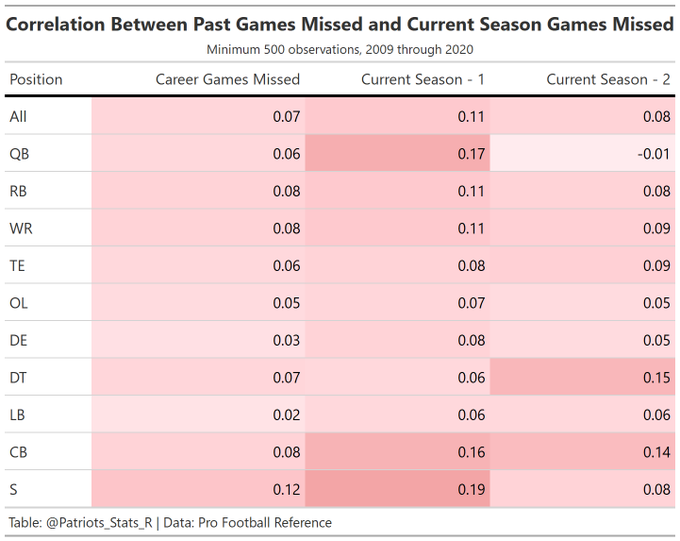
No real suprises here, the 49ers were heavily injured on both sides of the ball while the Bucs were relatively healthy throughout the season. The real interesting part of this is that most of the good defensive teams were the teams that just stayed healthy. This further supports the idea that defense is difficult to predict and an important aspect is simply staying healthy. But is it possible to predict injuries or do previous injuries provide little signal of the future? We can create a quick correlation plot to think about this question. It appears there is very little signal regarding a player’s injury history and their future games missed. Note that this does not delve deep into the specific injury types for players so it is possible certain injuries, such as a hamstring, may linger into the next season.